Finer04's Blog
首页
乱写一通
脑洞破文
随便谈谈
当前播放.page
某网站查询页面的辣鸡爬虫
Finer04
March 12, 2020
4542 字
文章目录
## 阅前须知 1. 由于该网站太顶风作案,域名我和谐了,懂的自然懂 2. 我还在学 py,代码过于辣鸡甚至没有优化,调用方法完全乱套 ## 背景 由于用公司研发部同事基于 Java 开发的某网站查询的爬虫用得太爽了,搞到我自己都想抄一份试试了,并在此之前通过百度“抄了”很多方法做了个多线程查询接口的小程序就有点膨胀了(其实代码还是一坨屎,而不需要太多字符串处理) 同事做的虽然速度很快,还特意为验证码做了训练识别率超高也很快,后来我反编译同事的源码发现用了阿里云的 OCR 服务,爷懂了,这就是在线识别的速度吗,爷i了(然后今天用回同事的工具发现他的API终于炸了,不能开心的批量查询了)。于是爷也去写了一份试试,跑一下!这么屑的识别率和查询错误率还有作为工具的必要吗? 但写都写了,虽然正确率不高但又不是不能用,反正以后写破代码还是得百度抄代码才能做,不如拿这篇文章当个草稿。  ## 实现 ### 分析正常查询过程 首先,这个网站主要通过 POST 带上 headers 和 验证码 data form 就可以得到结果了。但按照正常步骤来说,需要先通过验证码审核才可以确认提交。 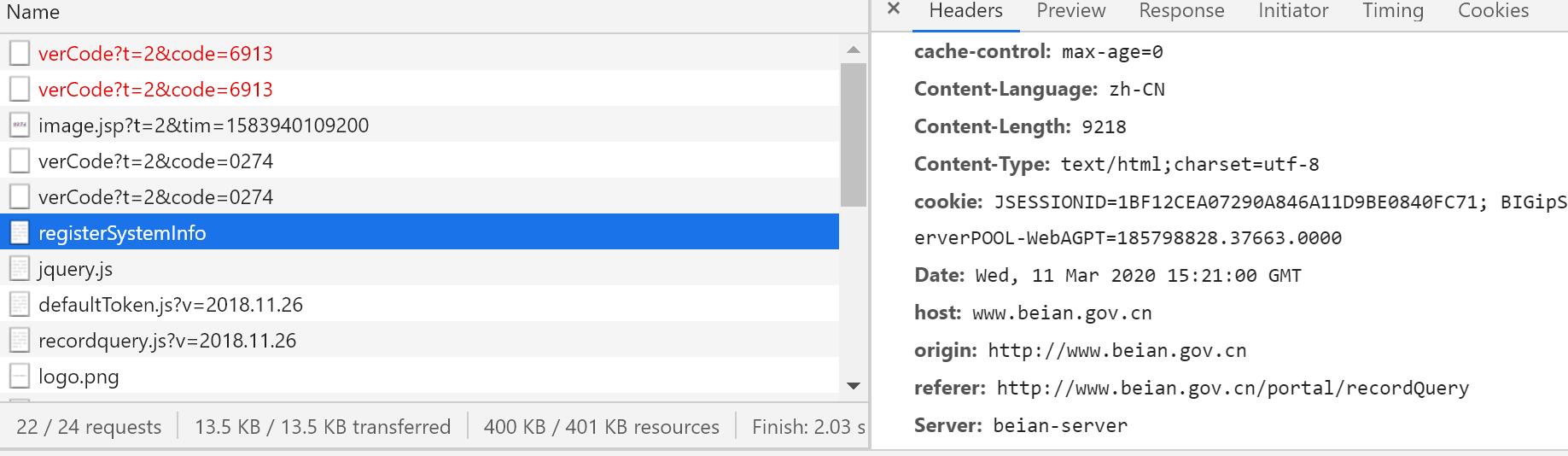 ### 验证码怎么办 目前 Python3 第三方可以识别 OCR 的库有 pytesseract,其实就是在 Tesseract 做了个连接,在 Windows 还是需要下载 Tesseract就行了。在识别方面,我前期仅做了灰度处理,因为不做也能正常识别到。为什么不加上只限定数字的config,emmmmm测试结果感觉有点不理想(那宁可以去做训练啊,不了不了我懒死了)。 我们先下载图片文件,因为下载到的内容是二进制,需要将数据写入到 code.jpg 中,写入完就交给 ocr 处理。 codepic = 'http://www.xxxx.cn/common/image.jsp?t=2' def ocrcode(picname): pic = Image.open(picname) pic1 = pic.convert('L') code1=(pytesseract.image_to_string(pic1)).replace('.','') time.sleep(2) return code1 # 先获取验证码图片 picurl = session.get(url=codepic,headers=headers,params=pame) data = picurl.content with open('code.jpg','wb') as f: f.write(data) f.close() # 验证码交给 ocr 识别 code = ocrcode('code.jpg') print(code) ### 要先设定好请求头信息 我佛了,当初像个憨憨直接提交数据,请求头就弄了个 UA 其他就不搞了,我还以为 requests 会持续使用响应的头信息,并不会并不会。结果要不出现 500 错误或者回到了查询页面,我的 dataform 应该没问题呀,然后我直接将浏览器的所有请求头信息全塞进去,牛批居然可以了。那就先弄个字典吧 "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36", "Referer" : 'http://www.xxxx.cn/portal/recordQuery', 'Host' : 'www.xxxx.cn', 'Origin' : 'www.xxxx.cn', 'Server': 'xxxx-server', 'token' : '', 'cookie' : '', 'X-Requested-With': 'XMLHttpRequest', 'Upgrade-Insecure-Requests': '1', "Content-Type": "application/x-www-form-urlencoded", } 虽然原本的头信息在现在是可以正常用,但 cookie 和 token 什么的会过一段时间过期,所以设定好头信息,就需要做一个如何获取这两个玩意的方法。 刚开始我就获取到 cookies 转换为字典后,post 数据直接带着 cookies,但提交后还是 500 错误,试了几百次还是这样,最后直接丢到 headers 居然tm的成功了,爷懂了,我这就去跟网站对线。 def getoken(): global cookie indexurl = requests.get(url=searchurl,headers=headers) html = indexurl.text #获取cookie cookie=indexurl.cookies.get_dict() # 利用正则搜索html的常量 for i in html.splitlines(): test = re.search(r"taken_for_user = '(.*)'",i) if test == None: continue else: token = test.groups(1)[0] break return token #获取token和cookie token = getoken() headers['token'] = token #格式化cookie,加入到headers headers['cookie'] = 'BIGipServerPOOL-WebAGPT=' + cookie['BIGipServerPOOL-WebAGPT'] + '; JSESSIONID=' + cookie['JSESSIONID'] print(headers['cookie']) print("token="+headers['token']) 关于 token 为什么要用正则找,当初我是想在 URL 获取的但太麻烦了,后来我在查询页面网站的源代码找到了开头的 javascript 已经有 token 的赋值字段了,那我直接正则匹配算了。cookie 也是复用这个方法,但正确来说不应该这么写。 ### 发送数据获取结果 好了,头信息和验证码爷都搞定了,那就试试呗。 先试试验证码能不能过验证,如果反馈了 `1` 就正确,反之错误,但这一步没有意义,因为我还没做验证码错误重新识别的判断。如果可以就提交给查询页面了。最后的输出成功的内容会有表格,只能用 BeautifulSoup 找到该字符串才行 # 获取完毕后,尝试将识别的数值来交给服务器验证 vercode = session.post(url=codevalidurl,headers=headers,cookies=cookie,params={'t':'2','code':code},data={'token' : headers['token']}) print(vercode.text) if vercode.text == '0': print('验证码出错') else: # 验证码通过,可以传参 register = session.post(url=recordurl,headers=headers,data={'token': headers['token'],'sdcx':'1','flag':'2','domainname':nowd,'inputPassword':code,}) #获得结果,匹配段落 resultlist = [] try: bf = BeautifulSoup(register.text,"html.parser") bf1 = bf.find('h5', text='网站所有者基本情况').parent tet = bf1.find_all('tr')[1].find_all('td')[1].contents[0] except Exception as e: print(register.headers) print(register.text) tet = '未备案或反爬虫了' print(nowd + ' : ' + tet) ### 结果 如果能输出内容,那就成功了。 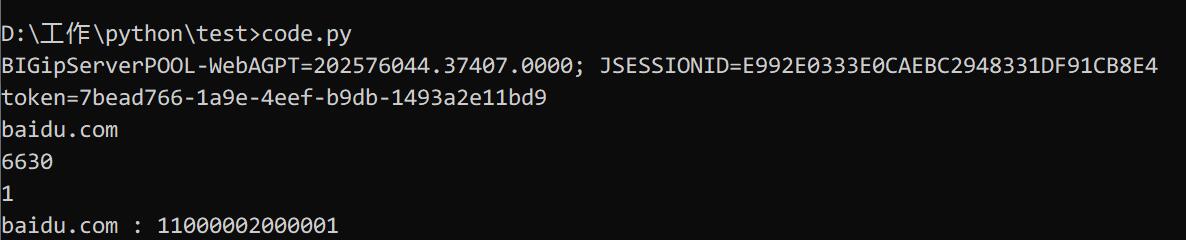
评论已关闭
▲ Top
评论已关闭