Finer04's Blog
首页
乱写一通
脑洞破文
随便谈谈
当前播放.page
记一次 ES 开启后整个系统崩掉的问题
Finer04
January 23, 2022
1677 字
文章目录
## 背景 上周五,本来和大学同学开开心心地去也是大学同学开的电玩店玩玩,但刚出发打车上车没过多久,手机就收到了 QQ 消息,值班同事跟我说: > “大佬,Kibana 开不起来了,怎么办!” 还好我们部门还没淘汰 KiwiSyslog,没有带电脑的我也没办法解决,以为重启下进程应该就能解决了,可值班同事重启进程后还是开不起来。唉算了算了等自己回宿舍再处理吧。本以为事情比较简单的,没想到回去后硬是整了一小时多才搞定。 ## 排障定位 我尝试了多种方法。如果 Kibana 开不起来的话,那就直接 `systemctl restart kibana` 就行了。值班重启后虽然服务没报错,但进入前端后就提醒了 `Kibana server is not ready yet`. 那我猜不关 Kibana 的事,难道是 Elasticsearch 数据库有问题? 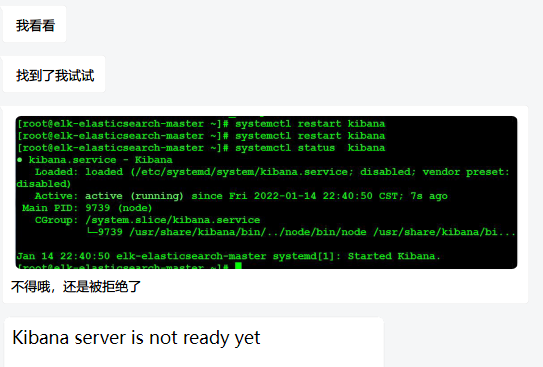 说一个比较蛋疼的要素,我把 ES 和 Kibana 都是放在一个服务器的,但 ES 的话我是弄了主节点和备节点,但这两个节点我是没做什么配置的,就只实现了数据共通而已,但脑裂了下备节点也没用了,所以就有单点故障的风险。先不管这个了,那就直接重启 elasticsearch 不就可以了吗,但重启了后还是这吊样,服务起不来。  上面的都是初步排障的过程,重启就能解决那就没必要去记录了。等到晚上的时候,我尝试再重启了 es 服务后,突然整个系统好像崩掉了,我一重启服务,再输入其他命令,但任何命令都报错了。我就关掉 SSH 再连进去,没想到 SSH 也连不上了明明端口是能通的,只能让机房给设备物理重启了。 重启后,ES 服务开机没启动,我自己手动启动后又这样了,感觉整个系统崩掉了只能让机房接个 KVM。接了 KVM 后再做同样的操作后,系统依然崩掉,但提示了报错内容: `Metadata CRC error detected at xfs_dir3_data read verify` 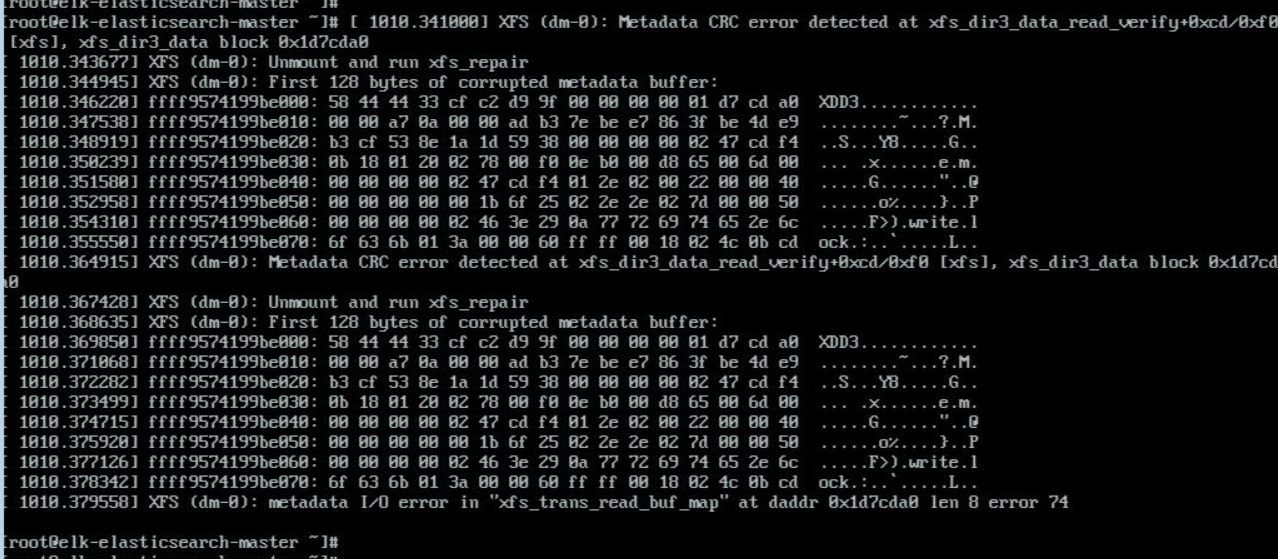 由于每天都接触交换机,对 CRC 已经是司空见惯了,可以判断是 xfs 分区校验有异常了。让机房现场同事看了眼 LED 屏没有报错信息,硬盘灯也没报错,那就可能是系统逻辑有问题了。 ## 解决 我是参考了这篇文章([https://blog.csdn.net/jycjyc/article/details/103073869](https://blog.csdn.net/jycjyc/article/details/103073869))来解决的。但是有个问题就是,我的 ELK 的数据是直接放在主分区的,无法 umount 的。文章说需要进救援模式,我尝试修改引导好像进不去,算了我接了 KVM 直接 `init 1` 进入单用户模式。 进入单用户模式后不用解除挂载,也不用 `xfs_check`,我直接 `xfs_repair -d /dev/mapper/centos-root` 开始修复。全过程也比较快,搞定后会提醒需要重启。 重启后,直接开启 elasticsearch 服务无异常,直接开 Kibana 也没问题。也趁这个机会我把数据转移到专用的数据盘了,以防到时候再次出现这种问题。得想办法处理这个单点故障吧,我这个伪分布式还是有问题的。
评论已关闭
▲ Top
评论已关闭